The mysterious case of the
shared storage pool that would not start...........after a power outage!
There was a power failure in our DC a while ago. This impacted one of our VIOS Shared Storage Pool (SSP) systems. We wanted to share with you the story of what happened when we tried to restart the VIOS SSP.
We had a single node VIOS SSP cluster (yes, you read that right, a single node). When electrical power was restored to the DC, we powered on the server and then activated the VIOS node. It booted fine, but the SSP failed to start.
The cluster -status command returned an error, stating that it was unable to connect to the (VIOS SSP) database.
[padmin@sys854-vios1]$
cluster -status
Unable
to connect to Database. Please check the filesystem space, network, and system
resources of the VIOS. If the error persists, contact your service
representative.
Unable
to connect to Database. Please check the filesystem space, network, and system
resources of the VIOS. If the error persists, contact your service
representative.
If you’re curious, this VIOS was running version 4.1 of the VIOS operating system.
[padmin@sys854-vios1]$
ioslevel
4.1.0.10
In the /home/ios/logs/viod.log log file we saw the following message repeated, over and over:
...
[2024-09-05
20:10:36.372] 0x1113 viod_primary.c
viod_read_lock_ecf
1.128.1.56 5269 ERR -- Unable to
get read lock on file
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/Election/dbn.ecf
errno:26
[2024-09-05
20:10:36.372] 0x1113 viod_primary.c
viod_get_primary_ecf
1.128.1.56 3399 ERR -- failed to
get ecf read lock rc: -1
...
The VIOS error report contained this information:
LABEL: POOL_START_FAILURE
IDENTIFIER: 042E4B14
Date/Time: Thu Sep
5 19:39:21 EDT 2024
Sequence
Number: 265
Machine
Id: 00CC53154C00
Node
Id: sys854-vios1
Class: S
Type: PERM
WPAR: Global
Resource
Name: POOL
Description
Pool
start failure.
Detail
Data
LINE
NUMBER:
740
DETECTING
MODULE
pool.c,Aug
29 2023 14:51:48 d2023_35A6
EVENT
DATA:
poolId=000000000A080C640000000065BAC357
psa_flags=0x8
0967-176
Resources are busy.
We noticed that the SSP file system was mounted. This was promising, as this meant that, although the SSP database was not fully operational, at least the data file system, containing all of the SSP volumes for our LPARs, was still intact.
[padmin@sys854-vios1]$
df | grep SSP
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310 837812224 775171864 8%
- - /var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310
[root@sys854-vios1]#
pooladm pool list
Pool
Path
------------------------------
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310
All we had to do now was determine what the problem was with the SSP database.
If you’re not aware, the VIOS uses Postgres as its database for storing the SSP configuration. On a VIOS with a properly functioning SSP setup, you’ll find Postgres processes running under the vpgadmin userid. For example:
[padmin@sys854-vios1]$
ps -fu vpgadmin
UID
PID PPID C
STIME TTY TIME CMD
vpgadmin 5046724 16253270 0
Sep 11 - 0:12 postgres: CM: background writer
vpgadmin
11206928 16253270 0 Sep 11
- 1:53 postgres: CM: checkpointer
vpgadmin
11469148 14811394 0 Sep 11
- 0:16 postgres: SSP: walwriter
vpgadmin
12452214 16253270 0 Sep 11
- 0:33 postgres: CM: walwriter
vpgadmin
13697434 14811394 0 Sep 11
- 0:00 postgres: SSP: autovacuum
launcher
vpgadmin
14090508 16253270 0 Sep 11
- 7:33 postgres: CM: logger
vpgadmin
14614900 14811394 0 Sep 11
- 0:00 postgres: SSP: logical
replication launcher
vpgadmin
14811394 13828406 0 Sep 11
- 22:24 /usr/ios/db/postgres15/bin/postgres -D
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L
vpgadmin
14876990 14811394 0 Sep 11
- 7:53 postgres: SSP: logger
vpgadmin
14942716 14811394 0 Sep 11
- 0:10 postgres: SSP: archiver
last was 000000010000000000000016.00000060.backup
vpgadmin
15597846 16253270 0 Sep 11
- 0:00 postgres: CM: autovacuum
launcher
vpgadmin
15925668 14811394 0 Sep 11
- 0:11 postgres: SSP:
checkpointer
vpgadmin
16253270 1 0
Sep 11 - 19:42
/usr/ios/db/postgres15/bin/postgres -D /home/ios/CM/DB
vpgadmin
16449904 14811394 0 Sep 11
- 0:11 postgres: SSP: background
writer
vpgadmin
17432894 16253270 0 Sep 11
- 0:01 postgres: CM: logical
replication launcher
[padmin@sys854-vios1]$
[root@sys854-vios1]#
/usr/ios/db/bin/postgres -V
/usr/ios/db/postgres15/bin/postgres
-V
postgres
(PostgreSQL) 15.3
We found some internal notes that suggested the error may be related to a corrupt dbn.ecf file. This file is important in a multi-node VIOS SSP cluster, as it is used to elect the primary node in the cluster. So, we tried the following steps to repair the file.
[root@sys854-vios1]#
lsattr -El cluster0 -a node_uuid
node_uuid
1e6a23e2-c084-11ee-8006-98be947267d2 OS image identifier True
[root@sys854-vios1]#
stopsrc -s vio_daemon
[root@sys854-vios1]#
rm
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG/postmaster.pid
[root@sys854-vios1]#
cd /var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/Election/
[root@sys854-vios1]#
mv dbn.ecf dbn.ecf.20240906.old
[root@sys854-vios1]#
echo "ecf_version:1" > dbn.ecf
[root@sys854-vios1]#
echo "cluster_id:1ea1377ec08411ee800698be947267d2" >>
dbn.ecf
[root@sys854-vios1]#
cat dbn.ecf
ecf_version:1
cluster_id:1ea1377ec08411ee800698be947267d2
[root@sys854-vios1]#
[root@sys854-vios1]#
startsrc -s vio_daemon
[root@sys854-vios1]#
lssrc -ls vio_daemon|grep DBN
DBN
NODE ID:
1e6a23e2c08411ee800698be947267d2
DBN
Role: Primary
To no avail. The same dbn.ecf errors appeared in the viod.log file and the problem remained. None of the vhostX adapters would configure.
[padmin@sys854-vios1]$
cfgdev
Some
error messages may contain invalid information
for
the Virtual I/O Server environment.
Method
error (/usr/lib/methods/cfg_vt_ngdisk -l vtscsi0 ):
0514-033 Cannot perform the requested
function because the
specified device is dependent
on an attribute which does
not exist.
Method
error (/usr/lib/methods/cfg_vt_ngdisk -l vtscsi1 ):
0514-033 Cannot perform the requested
function because the
specified device is dependent
on an attribute which does
not exist.
Method
error (/usr/lib/methods/cfg_vt_ngdisk -l vtscsi2 ):
0514-033 Cannot perform the requested
function because the
specified device is dependent
on an attribute which does
not exist.
Method
error (/usr/lib/methods/cfg_vt_ngdisk -l vtscsi3 ):
0514-033 Cannot perform the requested
function because the
specified device is dependent
on an attribute which does
not exist.
This particular VIOS was used for development purposes in our lab. Regular backups were not captured for this system, so, there was no mksysb (backupios) taken for this VIOS, prior to the power outage. However, we did find a couple of old (auto) SSP cluster backups in the cfgbackups directory in /home/padmin, from April of this year.
[padmin@sys854-vios1]$
ls -ltr cfgbackups
total
50208
-rw-r--r-- 1 padmin
staff 7164 Apr 22 22:00
autoviosbr_sys854-vios1.tar.gz
-rw-r--r-- 1 padmin
staff 25697221 Apr 22 22:01
autoviosbr_SSP.sys854sspcluster.tar.gz
These backups were automatically created when the VIOS and SSP configuration was last updated/changed. The following entry in root’s crontab enabled this feature:
[root@sys854-vios1]#
crontab -l | grep vio
0 *
* * * /usr/ios/sbin/autoviosbr -start 1>/dev/null 2>/dev/null
So, worst case, we did have a backup (although old) that we could use to recover the SSP configuration if needed.
Because we could still access the SSP file system, we decided to copy the SSP volumes (files) to another system, in case we needed to recover the LPARs. This would be a last resort!
We copied (scp'ed) the files in /var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VOL1
to another system.
[root@sys854-vios1]#
cd /var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310
[root@sys854-vios1]#
scp -pr VOL1 lpar1:/export/sys854_VOLS/
...
On the
remote system:
root@lpar1
/export/sys854_VOLS/VOL1 # ls -ltr
total
167772192
-rwx------ 1 root
system 21474836480 Jan 31
2024
an70lpar2-rootvg.048362b608a143c723fb0d23a4f623d5
-rwx------ 1 root
system 21474836480 Jan 31
2024
an70lpar3-rootvg.58843c5f94233028f17dfdfe9345fb46
--w------- 1 root
system 327 Jan 31
2024
.an70lpar1-rootvg.1880f7e6b63f621e0528bbfcbde91872
--w------- 1 root
system 327 Jan 31
2024
.an70lpar4-rootvg.3036fe48792a0471d56cf9c8af19c54e
--w------- 1 root
system 327 Jan 31
2024
.an70lpar2-rootvg.048362b608a143c723fb0d23a4f623d5
--w------- 1 root
system 327 Jan 31
2024
.an70lpar3-rootvg.58843c5f94233028f17dfdfe9345fb46
-rwx------ 1 root
system 21474836480 Jan 31
2024
an70lpar1-rootvg.1880f7e6b63f621e0528bbfcbde91872
-rwx------ 1 root
system 21474836480 Jan 31
2024
an70lpar4-rootvg.3036fe48792a0471d56cf9c8af19c54e
Our thought was that if we had to restore the SSP configuration from backup, or even worse, rebuild the VIOS SSP from scratch and reload the LPARs, we could use these SSP volume files. We recalled that there was a procedure we had used in the past to clone a SSP LPAR. The steps involve using the dd command to import an uncompressed copy of an SSP volume into a new (empty) SSP disk. You can review the procedure here:
Manually importing and exporting volumes
https://www.ibm.com/docs/en/powervc-cloud/2.2.1?topic=images-manually-importing-exporting-volumes
But, we really did not want to rebuild the whole environment again, as this would’ve required a lot of time and effort. Instead, we decided to persist with more troubleshooting.
The next thing we tried was to attempt to manually start the SSP DB.
[root@sys854-vios1]#
stopsrc -s vio_daemon
[root@sys854-vios1]#
lssrc -s vio_daemon
Subsystem Group PID Status
vio_daemon inoperative
[root@sys854-vios1]#
su - vpgadmin -c "export LIBPATH=/usr/ios/db/postgres15/lib;
/usr/ios/db/postgres15/bin/pg_ctl start -D
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG -l
/tmp/pg_ssp_db.log"
waiting
for server to start.... done
server
started
10:11
[root@sys854-vios1]#
cat /tmp/pg_ssp_db.log
2024-09-11
11:56:25.203 GMT [14876956] FATAL: lock
file "postmaster.pid" already exists
2024-09-11
11:56:25.203 GMT [14876956] HINT: Is
another postmaster (PID 5046584) running in data directory
"/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG"?
2024-09-11
11:58:43.108 GMT [14483778] LOG:
starting PostgreSQL 15.3 on powerpc-ibm-aix7.1.5.0, compiled by
/opt/IBM/xlc/13.1.0/bin/xlc -q64 -qcpluscmt, 64-bit
2024-09-11
11:58:43.109 GMT [14483778] LOG:
listening on IPv4 address "127.0.0.1", port 5432
2024-09-11
11:58:43.130 GMT [14483778] LOG:
listening on Unix socket "/tmp/.s.PGSQL.5432"
2024-09-11
11:58:43.154 GMT [12452114] LOG:
database system was shut down at 2024-09-11 11:57:08 GMT
2024-09-11
11:58:43.178 GMT [14483778] LOG:
database system is ready to accept connections
Then we checked to see of the DB processes were now up and listening.
# su
- vpgadmin -c "export LIBPATH=/usr/ios/db/postgres15/lib;
/usr/ios/db/postgres15/bin/pg_ctl status -D
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG"
# proctree
<pid SSP db>
# netstat
-Aan | grep 6090
It appeared that the database would come up for a little bit, then stop. Then it would attempt to restart again. Then stop again. It remained in this a loop forever.
[root@sys854-vios1]#
cg=`su
- vpgadmin -c "export LIBPATH=/usr/ios/db/postgres15/lib;
/usr/ios/db/postgres15/bin/pg_ctl status -D
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG"` ; echo
$cg | awk -F \) '{print $1}' | awk -F PID: '{print $2}' | xargs proctree ;
netstat -Aan | grep 6090
[root@sys854-vios1]#
cg=`su - vpgadmin -c "export LIBPATH=/usr/ios/db/postgres15/lib;
/usr/ios/db/postgres15/bin/pg_ctl status -D /v>
6554094 /usr/sbin/srcmstr
15073636
/usr/sbin/vio_daemon
17432844 /usr/ios/db/postgres15/bin/postgres -D
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_
5046530 postgres: background writer
9830694 postgres: checkpointer
12779940 postgres: walwriter
15335748 postgres: logical replication launcher
15663520 postgres: autovacuum launcher
f1000f0004ada3c0
tcp4 0 0
127.0.0.1.6090 . LISTEN
f1000f0007fda808
stream 0 0 f1000b02a466b020 0 0 0 /tmp/.s.PGSQL.6090
[root@sys854-vios1]#
cg=`su - vpgadmin -c "export LIBPATH=/usr/ios/db/postgres15/lib;
/usr/ios/db/postgres15/bin/pg_ctl status -D /v>
6554094 /usr/sbin/srcmstr
15073636
/usr/sbin/vio_daemon
17432844 /usr/ios/db/postgres15/bin/postgres -D
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_
5046530 postgres: background writer
9830694 postgres: checkpointer
12779940 postgres: walwriter
15335748 postgres: logical replication launcher
15663520 postgres: autovacuum launcher
f1000f0004ada3c0
tcp4 0 0
127.0.0.1.6090 . LISTEN
f1000f0004ae03c0
tcp4 0 0
127.0.0.1.45822
127.0.0.1.6090 TIME_WAIT
f1000f0004acf3c0
tcp4 0 0
127.0.0.1.45823
127.0.0.1.6090 TIME_WAIT
f1000f0007fda808
stream 0 0 f1000b02a466b020 0 0 0 /tmp/.s.PGSQL.6090
[root@sys854-vios1]#
cg=`su - vpgadmin -c "export LIBPATH=/usr/ios/db/postgres15/lib;
/usr/ios/db/postgres15/bin/pg_ctl status -D /v>
f1000f0004ae03c0
tcp4 0 0
127.0.0.1.45822
127.0.0.1.6090 TIME_WAIT
f1000f0004acf3c0
tcp4 0 0
127.0.0.1.45823
127.0.0.1.6090 TIME_WAIT
[root@sys854-vios1]#
This seemed to suggest there was a problem with the Postgres DB configuration. So, we decided to check contents of the postgresql.conf file.
[root@sys854-vios1]#
cat
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG/postgresql.conf
[root@sys854-vios1]#
We’d uncovered a huge problem!
The database configuration file was empty!
It was now no surprise that the database was not starting.
All we needed to do now was to find a way to recover, repair, or rebuild the postgresql.conf file. But how?
A sample postgresql.conf
file is provided with the ios.database.rte
fileset.
[root@sys854-vios1]#
lslpp -w /usr/ios/db/postgres15/share/postgresql/postgresql.conf.sample
File
Fileset Type
----------------------------------------------------------------------------
/usr/ios/db/postgres15/share/postgresql/postgresql.conf.sample
ios.database.rte File
root@sys854-vios1]#
lslpp -f | grep postgresql.conf
/usr/ios/db/postgres15/share/postgresql/postgresql.conf.sample
/usr/ios/db/postgres13/share/postgresql/postgresql.conf.sample
Our first thought was to copy the sample configuration file and make the necessary changes to suite the SSP environment.
# cp
/usr/ios/db/postgres15/share/postgresql/postgresql.conf.sample
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG/postgresql.conf
We stopped the DB and made a few edits to the config file,
including changing the listening port to 6090. We thought that perhaps the sample
postgres file would already be customised
(enough) for the VIOS SSP, but it wasn’t.
# su - vpgadmin
-c "export LIBPATH=/usr/ios/db/postgres15/lib;
/usr/ios/db/postgres15/bin/pg_ctl stop -D
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG"
# vi
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG/postgresql.conf
...
#port = 5432 #
(change requires restart)
port = 6090
...
This didn’t help much. The database continued attempting to start, failing and then restarting again. We were probably missing something in the configuration file and it was proving difficult (and time consuming) to figure out what was wrong or missing in this file. There were many items that needed to be changed in the sample file, for the VIOS SSP. For example:
...
max_connections
= 256 # (change
requires restart)
...
log_directory
= '/home/ios/logs/pg_sspdb' #
directory where log files are written,
# can
be absolute or relative to PGDATA
log_filename
= 'pg_sspdb-%d-%H-%M.log' # log file
name pattern,
# can
include strftime() escapes
log_file_mode
= 0644 # creation mode
for log files,
# begin
with 0 to use octal notation
log_truncate_on_rotation
= off # If on, an existing log
file with the
# same
name as the new log file will be
#
truncated rather than appended to.
# But
such truncation only occurs on
#
time-driven rotation, not on restarts
# or
size-driven rotation. Default is
# off,
meaning append to existing files
# in
all cases.
log_rotation_age
= 1d # Automatic
rotation of logfiles will
#
happen after that time. 0 disables.
log_rotation_size
= 20MB # Automatic
rotation of logfiles will
#
happen after that much log output.
# 0
disables.
…
We also considered copying a config file from another, different VIOS SSP cluster (as we had few other SSP clusters in the environment to work from). But we decided against it.
One of our colleagues, from the VIOS development team, indicated that a (backup) copy of the customised postgres configuration file was kept in the /usr/ios/db/configuration_files directory on the VIOS.
[root@sys854-vios1]#
ls -ltr /usr/ios/db/configuration_files/postgresql_SSP.conf
-rw-r--r-- 1 root
db_users 23349 Jul 25
2023
/usr/ios/db/configuration_files/postgresql_SSP.conf
We were advised to copy this file over the top of the (empty) /var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG/postgresql.conf file.
[root@sys854-vios1]#
ls -ltr /usr/ios/db/configuration_files/postgresql_SSP.conf
-rw-r--r-- 1 root
db_users 23349 Jul 25
2023
/usr/ios/db/configuration_files/postgresql_SSP.conf
[root@sys854-vios1]#
ls -ltr
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG/postgresql.conf
-rw-r--r-- 1 vpgadmin db_users 23349 Sep 11 08:14
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG/postgresql.conf
Then we attempted to start the database again.
# su
- vpgadmin -c "export LIBPATH=/usr/ios/db/postgres15/lib;
/usr/ios/db/postgres15/bin/pg_ctl start -D
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG -l
/tmp/pg_ssp_db.log"
The situation immediately looked a lot better. The netstat command showed lots of database port (listening) activity.
[root@sys854-vios1]#
/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG -l
/tmp/pg_ssp_db.log" <
waiting
for server to start.... done
server
started
[root@sys854-vios1]#
netstat -Aan | grep 6090
f1000f00069f43c0
tcp4 0 0
10.8.12.100.37575
10.8.12.100.6090 TIME_WAIT
f1000f00068383c0
tcp4 0 0
10.8.12.100.37576
10.8.12.100.6090 TIME_WAIT
f1000f0006840bc0
tcp4 0 0
10.8.12.100.37577
10.8.12.100.6090 TIME_WAIT
f1000f0006b3f3c0
tcp4 0 0
10.8.12.100.37578
10.8.12.100.6090 TIME_WAIT
f1000f00068debc0
tcp4 0 0
10.8.12.100.37579
10.8.12.100.6090 TIME_WAIT
f1000f00068dc3c0
tcp4 0 0
10.8.12.100.37580
10.8.12.100.6090 TIME_WAIT
f1000f00068b03c0
tcp4 0 0
10.8.12.100.37581
10.8.12.100.6090 TIME_WAIT
f1000f00068c43c0
tcp4 0 0
10.8.12.100.37582
10.8.12.100.6090 TIME_WAIT
f1000f0006891bc0
tcp4 0 0
10.8.12.100.37583
10.8.12.100.6090 TIME_WAIT
f1000f0004ad73c0
tcp4 0 0
10.8.12.100.37584
10.8.12.100.6090 TIME_WAIT
f1000f0004af03c0
tcp4 0 0
10.8.12.100.6090
10.8.12.100.37585 TIME_WAIT
f1000f00068583c0
tcp4 0 0
10.8.12.100.37586
10.8.12.100.6090 TIME_WAIT
f1000f00068563c0
tcp4 0 0
10.8.12.100.37587
10.8.12.100.6090 TIME_WAIT
f1000f0006855bc0
tcp4 0 0
10.8.12.100.37588
10.8.12.100.6090 TIME_WAIT
f1000f0006859bc0
tcp4 0 0
10.8.12.100.37589
10.8.12.100.6090 TIME_WAIT
f1000f0004acdbc0
tcp4 0 0
10.8.12.100.37590
10.8.12.100.6090 TIME_WAIT
f1000f0004afc3c0
tcp4 0 0
10.8.12.100.37591
10.8.12.100.6090 TIME_WAIT
f1000f00068553c0
tcp4 0 0
10.8.12.100.37592
10.8.12.100.6090 TIME_WAIT
f1000f00068af3c0
tcp4 0 0
10.8.12.100.37593
10.8.12.100.6090 TIME_WAIT
f1000f00068593c0
tcp4 0 0
10.8.12.100.37594
10.8.12.100.6090 TIME_WAIT
f1000f0006854bc0
tcp4 0 0
10.8.12.100.6090
10.8.12.100.37595 TIME_WAIT
f1000f0004ac6bc0
tcp4 0 0
10.8.12.100.37596
10.8.12.100.6090 TIME_WAIT
f1000f0004b083c0
tcp4 0 0
10.8.12.100.6090
10.8.12.100.37597 TIME_WAIT
f1000f0004add3c0
tcp4 0 0
10.8.12.100.37598
10.8.12.100.6090 TIME_WAIT
f1000f0004ac63c0
tcp4 0 0
10.8.12.100.37599
10.8.12.100.6090 TIME_WAIT
f1000f0004ac73c0
tcp4 0 0
10.8.12.100.37600
10.8.12.100.6090 TIME_WAIT
f1000f0004b043c0
tcp4 0 0
10.8.12.100.37601
10.8.12.100.6090 TIME_WAIT
f1000f00006453c0
tcp4 0 0
10.8.12.100.37602
10.8.12.100.6090 TIME_WAIT
f1000f00006e3bc0
tcp4 0 0
10.8.12.100.37603
10.8.12.100.6090 TIME_WAIT
f1000f0006890bc0
tcp4 0 0
10.8.12.100.37604
10.8.12.100.6090 TIME_WAIT
f1000f00068543c0
tcp4 0 0
10.8.12.100.6090
10.8.12.100.37605 TIME_WAIT
f1000f0004afe3c0
tcp4 0 0
10.8.12.100.37606
10.8.12.100.6090 TIME_WAIT
f1000f0004ac7bc0
tcp4 0 0
10.8.12.100.37607
10.8.12.100.6090 TIME_WAIT
f1000f00068903c0
tcp4 0 0
10.8.12.100.37608
10.8.12.100.6090 TIME_WAIT
f1000f000684b3c0
tcp4 0 0
10.8.12.100.6090
10.8.12.100.37609 TIME_WAIT
f1000f00068c3bc0
tcp4 0 0
10.8.12.100.37618
10.8.12.100.6090 TIME_WAIT
f1000f00068e03c0
tcp4 0 0
10.8.12.100.37619
10.8.12.100.6090 TIME_WAIT
f1000f0006892bc0
tcp4 0 0
10.8.12.100.37621
10.8.12.100.6090 TIME_WAIT
f1000f000685a3c0
tcp4 0 0
10.8.12.100.37622
10.8.12.100.6090 TIME_WAIT
f1000f0004ad03c0
tcp4 0 0
10.8.12.100.37623
10.8.12.100.6090 TIME_WAIT
f1000f0004af6bc0
tcp4 0 0
10.8.12.100.6090
10.8.12.100.37624 TIME_WAIT
f1000f00068db3c0
tcp6 0 0
*.6090 . LISTEN
f1000f00068573c0
tcp4 0 0
*.6090 . LISTEN
f1000f00069f9808
stream 0 0 f1000b02a531a820 0 0 0 /tmp/.s.PGSQL.6090
[root@sys854-vios1]#
The database now appeared to be running and stable.
[root@sys854-vios1]#
su - vpgadmin -c "export
LIBPATH=/usr/ios/db/postgres15/lib; /usr/ios/db/postgres15/bin/pg_ctl status -D
/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG"
pg_ctl:
server is running (PID: 14811394)
/usr/ios/db/postgres15/bin/postgres
"-D"
"/var/vio/SSP/sys854sspcluster/D_E_F_A_U_L_T_061310/VIOSCFG/DB/PG"
"-p" "6090"
The /home/ios/logs/vdba.log file showed that the database was RUNNING. Previously, this file had been empty, even when we had tried to start the database (unsuccessfully) numerous times during our troubleshooting process.
[root@sys854-vios1]#
tail /home/ios/logs/vdba.log
VDBA
ENDING: PID = 5046600 | Completed at: 11-Sep-2024 07:57:09 | rc = 0
[12714460 11-Sep-2024 11:57:09] dba_db.c 1.5.2.6 stop_op_handler @ 560 : CM database is now STOPPED.
VDBA
ENDING: PID = 12714460 | Completed at: 11-Sep-2024 11:57:09 | rc = 0
VDBA
STARTING: PID = 15401420 | Started at: 11-Sep-2024 12:21:27
[15401420 11-Sep-2024 12:21:27] vdba.c 1.3.1.4 get_valid_input @ 263 : argv[1] = -cm
[15401420 11-Sep-2024 12:21:27] vdba.c 1.3.1.4 get_valid_input @ 263 : argv[2] = -start
[15401420 11-Sep-2024 12:21:27] vdba.c 1.3.1.4 get_valid_input @ 409 : @@@ op = 'OP_START', db = 'DB_CM'
[15401420 11-Sep-2024 12:21:27] dba_db.c 1.5.2.6 vdba_popen @ 618 : Incoming cmd='su - vpgadmin -c
"export LIBPATH=/usr/ios/db/postgres15/lib;
/usr/ios/db/postgres15/bin/pg_ctl start -w -D /home/ios/CM/DB"'
[15401420 11-Sep-2024 12:21:27] dba_db.c 1.5.2.6 start_op_handler @
491 : CM database is now RUNNING.
VDBA
ENDING: PID = 15401420 | Completed at: 11-Sep-2024 12:21:27 | rc = 0
We were able to run a couple of Postgres psql commands to test connections to the database. They were all successful. This was good news.
[root@sys854-vios1]#
/usr/ios/db/bin/psql -U vpgadmin -l -p 6080 -P pager=off
List
of databases
Name
| Owner | Encoding | Collate | Ctype | ICU Locale |
Locale Provider | Access privileges
-----------+-----------+----------+---------+-------+------------+-----------------+-----------------------
postgres
| vpgadmin | LATIN1 | en_US
| en_US | | libc |
template0 | vpgadmin | LATIN1
| en_US | en_US | | libc | =c/vpgadmin +
| | | |
| | | vpgadmin=CTc/vpgadmin
template1 | vpgadmin | LATIN1
| en_US | en_US | | libc | =c/vpgadmin +
| | | |
| | | vpgadmin=CTc/vpgadmin
vioscm
| viosadmin | LATIN1 |
en_US | en_US | | libc |
(4
rows)
[root@sys854-vios1]#
export LIBPATH=/usr/ios/db/postgres15/lib
[root@sys854-vios1]#
export PGPASSWORD=_`lsattr -El vioscluster0 -a cluster_id -F value`
[root@sys854-vios1]#
/usr/ios/db/postgres15/bin/psql -p 6090 -U viosadmin -d postgres -c 'SELECT
datname, datallowconn FROM pg_database;'
datname
| datallowconn
-----------+--------------
postgres
| t
vios
| t
template1 | t
template0 | f
(4
rows)
[root@sys854-vios1]#
/usr/ios/db/bin/psql -U vpgadmin -d vios -p 6090 -P pager=off
psql
(15.3)
Type
"help" for help.
vios=#
\dbn
List of tablespaces
Name
| Owner | Location
------------+----------+----------
pg_default | vpgadmin |
pg_global
| vpgadmin |
(2
rows)
vios=#
\dn
List of schemas
Name
| Owner
--------+-------------------
public | pg_database_owner
vios |
viosadmin
(2
rows)
vios=#
\dt vios.*
List of relations
Schema | Name | Type |
Owner
--------+------------------------+-------+-----------
vios |
capability | table |
viosadmin
vios |
client_partition | table |
viosadmin
vios |
clientimage | table |
viosadmin
vios |
clientop | table |
viosadmin
vios |
cluster_version | table |
viosadmin
vios |
disk | table |
viosadmin
vios |
event | table |
viosadmin
vios |
event_attribute | table |
viosadmin
vios |
failure_group | table |
viosadmin
vios |
file | table |
viosadmin
vios |
fileset | table |
viosadmin
vios |
filetotier | table |
viosadmin
vios |
importpv | table |
viosadmin
vios |
lu | table |
viosadmin
vios |
map | table |
viosadmin
vios |
master_image | table |
viosadmin
vios |
node_version | table |
viosadmin
vios |
nodecaching | table |
viosadmin
vios |
partition | table |
viosadmin
vios |
resource | table |
viosadmin
vios |
sp_threshold_alert | table |
viosadmin
vios |
storage_pool | table |
viosadmin
vios |
tier | table |
viosadmin
vios |
tier_threshold_alert | table |
viosadmin
vios |
transaction | table |
viosadmin
vios |
vios_cluster | table |
viosadmin
vios |
virtual_log | table |
viosadmin
vios |
virtual_log_repository | table | viosadmin
vios |
virtual_server_adapter | table | viosadmin
(29
rows)
vios=#
\q
[root@sys854-vios1]#
The real test was to run the cluster -status command and see if it would report that status of the cluster, successfully.
[padmin@sys854-vios1]$
cluster -status
Cluster
Name State
sys854sspcluster OK
Node Name MTM Partition Num State
Pool State
sys854-vios1 8286-41A0206C5315 1
OK OK
It worked!
And the people rejoiced and there was singing in the
streets…..
The lu command successfully displayed all of the SSP volumes.
[padmin@sys854-vios1]$
lu -list
POOL_NAME:
sys854ssp
TIER_NAME:
SYSTEM
LU_NAME SIZE(MB) UNUSED(MB) UDID
an70lpar1-rootvg
20480
15510 1880f7e6b63f621e0528bbfcbde91872
an70lpar2-rootvg 20480 16160 048362b608a143c723fb0d23a4f623d5
an70lpar3-rootvg 20480 16160 58843c5f94233028f17dfdfe9345fb46
an70lpar4-rootvg 20480 15468 3036fe48792a0471d56cf9c8af19c54e
We were then able to configure the vhostX devices.
[padmin@sys854-vios1]$
cfgdev
[padmin@sys854-vios1]$
lsmap -all
SVSA Physloc Client
Partition ID
---------------
-------------------------------------------- ------------------
vhost0 U8286.41A.06C5315-V1-C50 0x00000002
VTD vcd0
Status Available
LUN 0x8100000000000000
Backing
device
Physloc
Mirrored N/A
VTD vtscsi0
Status Available
LUN 0x8200000000000000
Backing
device
an70lpar1-rootvg.1880f7e6b63f621e0528bbfcbde91872
Physloc
Mirrored N/A
SVSA Physloc Client
Partition ID
---------------
-------------------------------------------- ------------------
vhost1 U8286.41A.06C5315-V1-C54 0x00000004
VTD vcd3
Status Available
LUN 0x8100000000000000
Backing
device
Physloc
Mirrored N/A
VTD vtscsi3
Status Available
LUN 0x8200000000000000
Backing
device
an70lpar4-rootvg.3036fe48792a0471d56cf9c8af19c54e
Physloc
Mirrored N/A
SVSA Physloc Client
Partition ID
---------------
-------------------------------------------- ------------------
vhost2 U8286.41A.06C5315-V1-C52 0x00000003
VTD vcd1
Status Available
LUN 0x8100000000000000
Backing
device
Physloc
Mirrored N/A
VTD vtscsi1
Status Available
LUN 0x8200000000000000
Backing
device
an70lpar2-rootvg.048362b608a143c723fb0d23a4f623d5
Physloc
Mirrored N/A
SVSA Physloc Client
Partition ID
---------------
-------------------------------------------- ------------------
vhost3 U8286.41A.06C5315-V1-C53 0x00000005
VTD vcd2
Status Available
LUN 0x8100000000000000
Backing
device
Physloc
Mirrored N/A
VTD vtscsi2
Status Available
LUN 0x8200000000000000
Backing
device
an70lpar3-rootvg.58843c5f94233028f17dfdfe9345fb46
Physloc
Mirrored N/A
[padmin@sys854-vios1]$
Finally, we successfully started all of the LPARs.
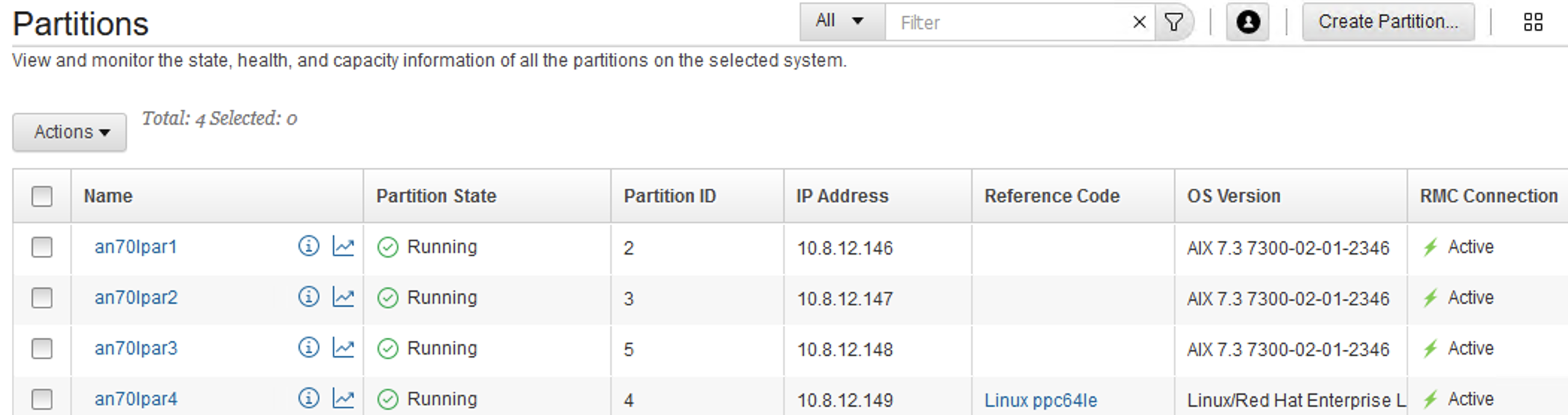
The HMC UI also reported a healthy SSP cluster.
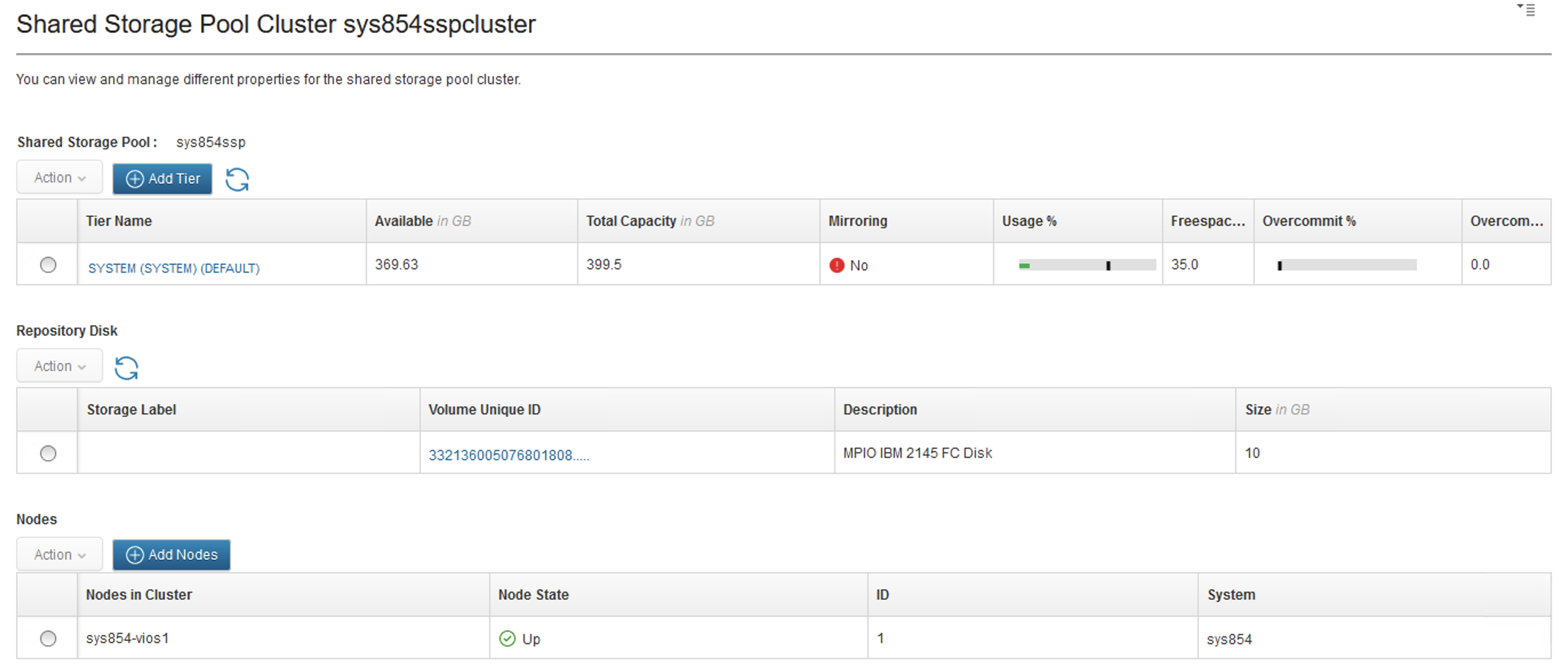
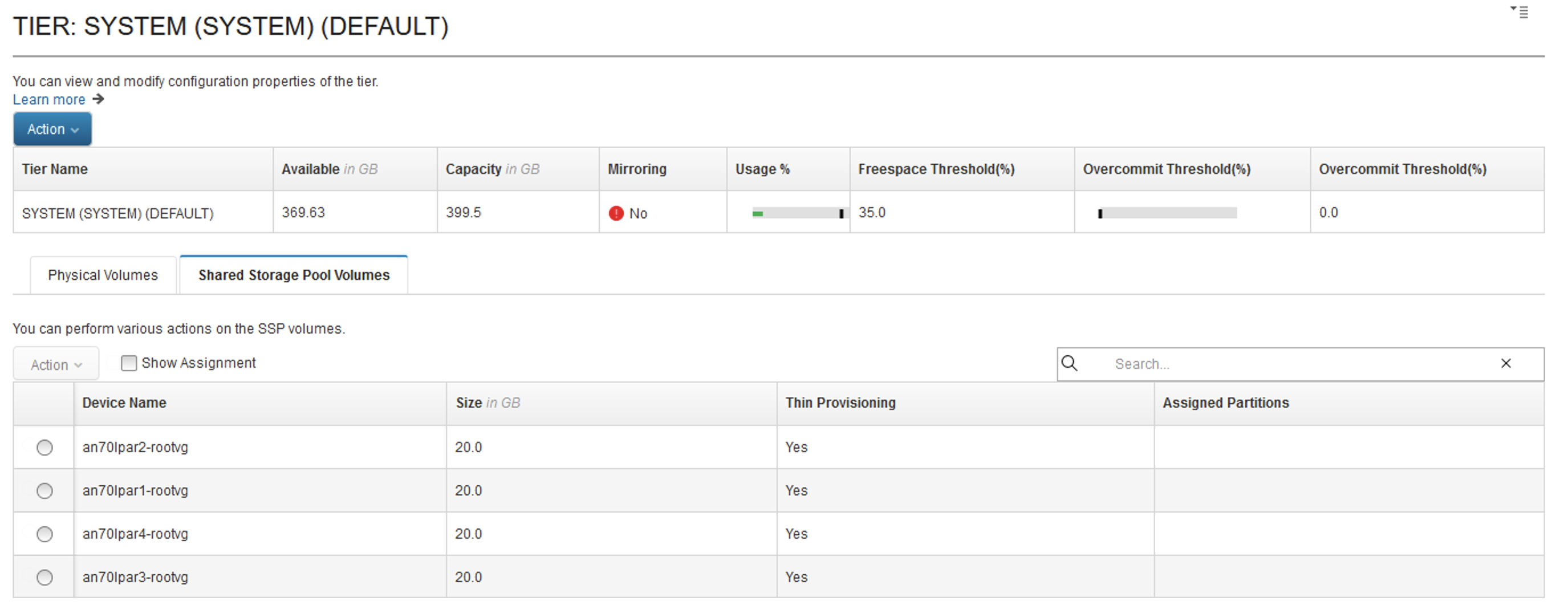
This brings us to the end of our mysterious tale. What
started out as an error message stating 0967-176 Resources are busy turned
out to be a problem with an empty database configuration file. It would’ve been
really nice if there had been some sort of message, in one of the log files, somewhere,
that had given us some sort of clue that the DB config file was corrupt or empty.
We, of course, shared this thought the VIOS SSP development team.
Of course, most people will never need to know or care about the SSP database or the fact that a Postgres database is running underneath. We were just unlucky. The power outage likely caused some sort of corruption (although we can’t be 100% certain). In other words, most VIOS SSP users will never need to read this blog post. We’re thankful for this.
Until next time.
FYI: Here’s a copy of our SSP postgres config file (for reference): http://gibsonnet.net/aix/ibm/postgresql_SSP.conf.txt
Note: The SSP DB changed over time, for all SSP cluster before VIOS 2.2.6.31 the database was SolidDB, but later version have been migrated to PostgreSQL. So if all your node in the cluster are reporting as ON_LEVEL with version older than .2.6.31, then the DB should be SolidDB. If all your node are ON_LEVEL with version 2.2.6.31 or higher, then it should be a PostgreSQL DB.
You can check this with the ps command:
·
For SolidDB, you’ll see “soliddb” process from
root user.
·
For PostgreSQL, you’ll see multiple “postgres”
process from vpgadmin user.
Here are the port number for each DB :
·
For SolidDB : 3801/tcp (marked as unassigned in
“/etc/services”)
·
For PostgreSQL : 6080/tcp & 6090/tcp (not in
“/etc/services”)
More information here: https://www.ibm.com/support/pages/how-setup-vios-firewall-ssp-cluster-environment
The Implementing IBM VM Recovery Manager for IBM Power Systems Redbook contains some more information about the SSP database, in the "The SSP cluster and HSDB database" section of the book (Pages 122 to 142): https://www.redbooks.ibm.com/abstracts/sg248426.html